Speicherlayout von Datenstrukturen#
Dieses Kapitel bietet detaillierte Informationen darüber, wie Datenstrukturen im Arbeitsspeicher organisiert werden. Diese Informationen sind für das Verständnis der Effizienz verschiedener Operationen wichtig, sind aber nicht zwingend erforderlich für die praktische Programmierung.
Grundlagen des Arbeitsspeichers#
Über die Geschichte hinweg hat sich der Arbeitsspeicher in Geschwindigkeit und Größe und bezüglich anderer Eigenschaften weiterentwickelt. Was uns jedoch interessiert sind die wenigen grundlegenden Eigenschaften, die wir als Programmierer*in beachten müssen:
- Ordnung
Der Arbeitsspeicher ist im Wesentlichen eine lange geordnete Ansammlung an Bits
- Addressierbarkeit
Diese Bits sind addressierbar/indexierbar
- Effizienz
Die Adressierung eines Bits für eine gegebene Adresse ist sehr effizient
Die Eigenschaft der effizienten Adressierung spiegelt sich in allen Programmiersprachen mehr oder weniger pregnannt wieder. Gewöhnlich adressiert die CPU keine einzelnen Bits, sondern ein ganzes Byte. Abbildung 8 zeigt ein Beispiel eines Arbeitsspeichers der uns erlaubt jeweils ein Byte zu adressieren. Zugleich werden Adressen, in diesem Beispiel, durch ein Byte dargestellt.
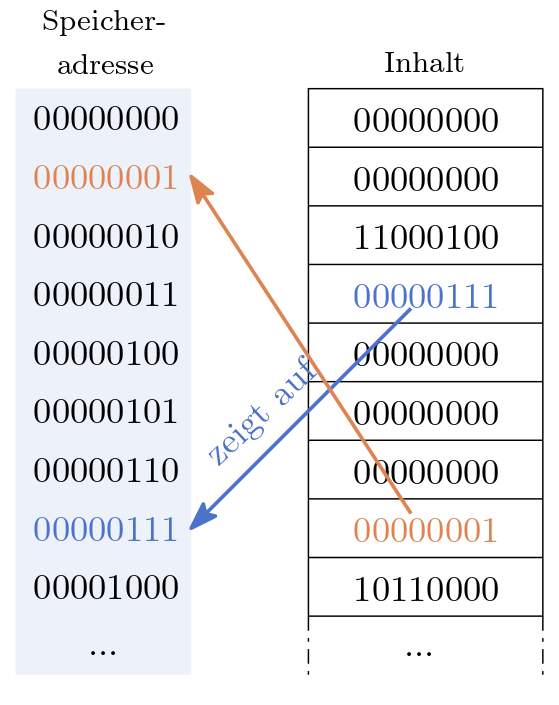
Abb. 8 Der Arbeitsspeicher ist eine sehr lange Liste bestehend aus Bits. Die Adresse (links) ist im Wesentlichen die Nummer / der Index eines bestimmten Speicherplatzes (rechts). Alle Werte sind im Binärsystem dargestellt. An Adresse 00000111 befindet sich eine Adresse.#
Exercise 4 (Adressraum)
Wie viel Byte können im Beispiel von Abbildung 8 maximal adressiert werden?
Solution to Exercise 4 (Adressraum)
Der Adressraum geht von \(0000\,0000_2\) bis \(1111\,1111_2\). Das heißt von \(0_{10}\) bis \(1\,0000\,0000_2 - 1_2 = 2^8-1 = 256-1 = 255\). Da jede Adresse ein Byte adressiert, können wir somit lediglich \(256\) Byte adressieren.
Exercise 5 (32-Bit-Adressraum)
Weshalb war es vor Jahren nicht möglich mehr als ca. 4 GiB Arbeitsspeicher im Rechner zu verwenden?
Hinweis: Es ereignete sich ein Wechsel von einer 32-Bit auf eine 64-Bit Adressierung.
Solution to Exercise 5 (32-Bit-Adressraum)
Mit \(32\) bildet sich ein Adressraum von \(2^{32}\) Adressen. Wenn die CPU jedes einzelne Byte adressieren können soll, so ergibt sich ein Maximum an
Byte und das sind \(2^{10} \cdot 2^{10} \cdot 2^2\) KiB, \(2^{10} \cdot 2^2\) MiB bzw. \(4\) GiB.
Statische Sammlungen im Speicher#
Das Prinzip ist einfach: Die Datenstruktur, inklusiver ihrer Elemente, wird durch einen zusammenhängenden Speicherbereich realisiert.
Exercise 6 (Schließfächer)
Stellen Sie sich den Arbeitsspeicher als eine Ansammlung von nummerierten Schließfächern vor. Angenommen Sie können frei über diese Schließfächer bestimmen. Sie wollen 10 Gegenstände, wobei jedes dieser Gegenstände den Platz von einem Schließfach verbraucht, lagern. Mit welcher Strategie müssen Sie sich am wenigsten merken um ihre Gegenstände wiederzufinden?
Solution to Exercise 6 (Schließfächer)
Sie wählen ein beliebige Schließfach (nicht zu weit hinten) aus und legen alle Gegenstände in aufeinderfolgende Schließfächer ab. Sie müssen sich lediglich die Nummer des einen Schließfachs und die Anzahl der Gegenstände merken.
Die Aufgabe verrät uns den wesentlichen Vorteil, wenn wir Daten im Verbund, d.h. in einem zusammenhängenden Speicherbereich ablegen. Es ist uns möglich diese Daten sehr einfach wiederzufinden. Wir müssen uns nur eine Speicheradresse merken!
Wollen wir, z.B., die Ziffern einer ISBN-Nummer abspeichern, so könnten wir diese Ziffern nebeneinander im Speicher ablegen. Wir merken uns bei welcher Adresse die ISBN-Nummer beginnt und wie viele Stellen sie hat. Eine solche Datenstruktur realisiert das sog. Array.
Datenstrukturen realisiert als zusammenhängender Speicherbereich haben Vor- und Nachteile, welche uns das Schließfachbeispiel gut veranschaulicht. Wenn Sie, z.B., auf den dritten Gegenstand (wir beginnen bei 0) zugreifen wollen, können Sie das Schließfach in Windeseile auffinden. Sie gehen zum Schließfach dessen Nummer Sie kennen und wandern dann vier Schließfächer nach, z.B. rechts. Da jedes Schließfach gleich breit ist, müssen Sie nicht einmal auf die anderen Schließfächer blicken und können einen großen Schritt der Länge 4 mal \(c\) Meter nach z.B. rechts wandern. Sie können den Abstand zwischen dem 0-ten und 3-ten Gegenstand (mit einfachen arithmetischen Mitteln) berechnen.
Genauso verhält es sich mit den Adressen des Speichers. Kennen wir die Adresse \(x_0\) des 0-ten Elements/Gegenstands und wissen wie viele Bits jeder Gegenstand verbraucht, sagen wir \(c\) Bits, können wir die Adresse des \(i\)-ten Elements durch
berechnen. Deshalb ist die Indexierung eines Elements enorm effizient. Voraussetzung ist jedoch, dass jedes Element durch genau \(c\) Bits repräsentiert wird. Die folgende Abbildung veranschaulicht die Indexierung. Dabei ist in blau der von der Datenstruktur belegte Speicher hervorgehoben. Die grauen Bereiche sind ebenfalls belegt jedoch nicht von unserer Datenstruktur.

Abb. 9 Listen-Index#
Was aber wenn Sie einen weiteren Gegenstand in den Zusammenschluss aus Schließfächern einfügen wollen und zwar mitten drinnen? Dann müssen Sie viele Gegenstände aus Schließfach \(k\) in das Schließfach \(k+1\) bewegen. Folgende Abbildung skizziert diesen aufwendigen Vorgang:
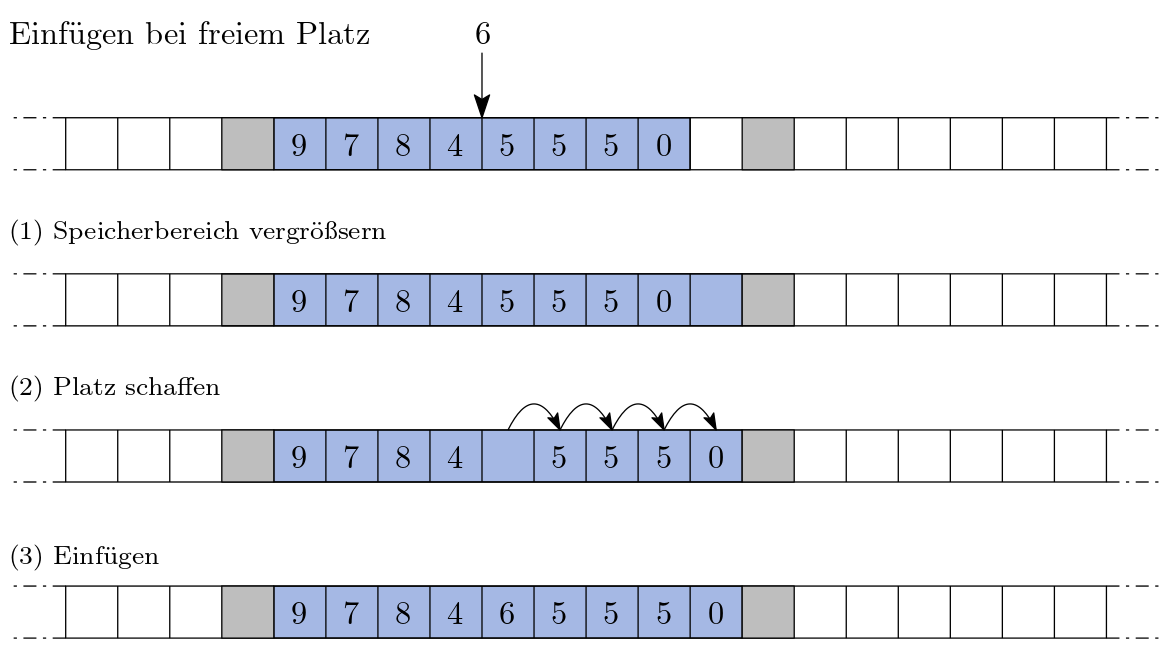
Abb. 10 Einfügen eines Elements#
Und was passiert wenn das darauffolgende Schließfach von jemandem anderen belegt ist? Dann müssten Sie alle Gegenstände in eine neue Folge aus zusammenhängende Schließfächer befördern Sie müssen dafür natürlich eine Stelle finden, die genug Platz bietet! Die folgende Abbildung skizziert diesen Vorgang:
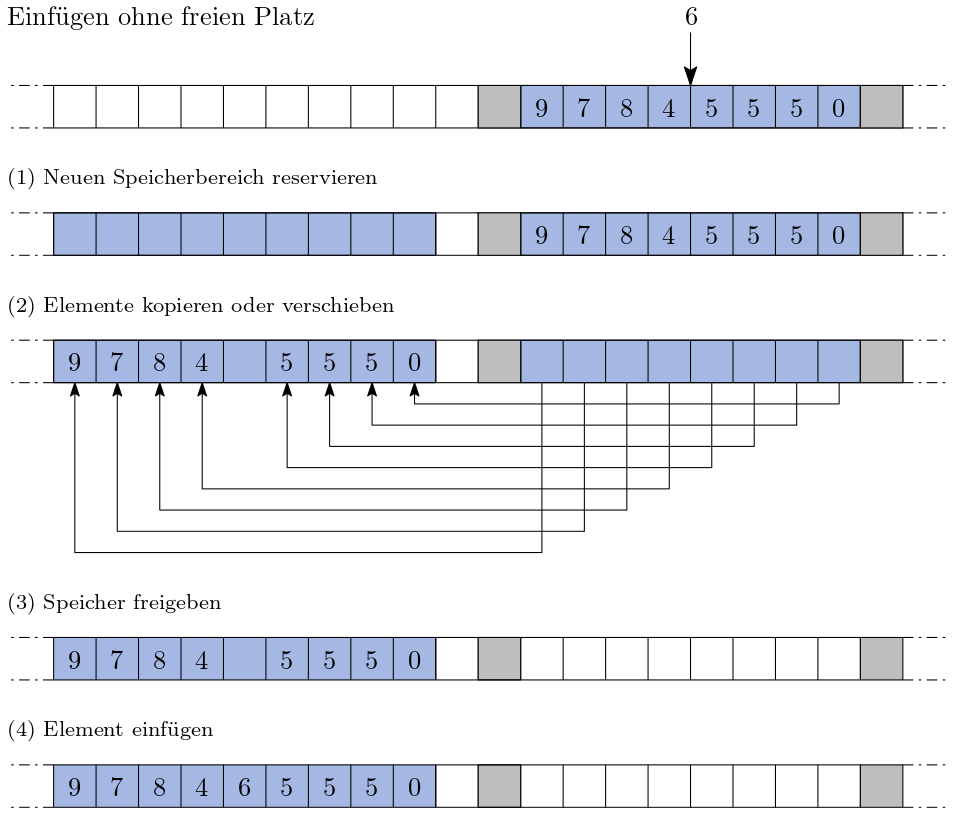
Abb. 11 Kein Platz#
Wenn Sie einen Gegenstand inmitten der Schließfächer löschen, müssen Sie ebenfalls viele Gegenstände bewegen. Dieser Vorgang ähnelt dem Einfügen inmitten der Datenstruktur.
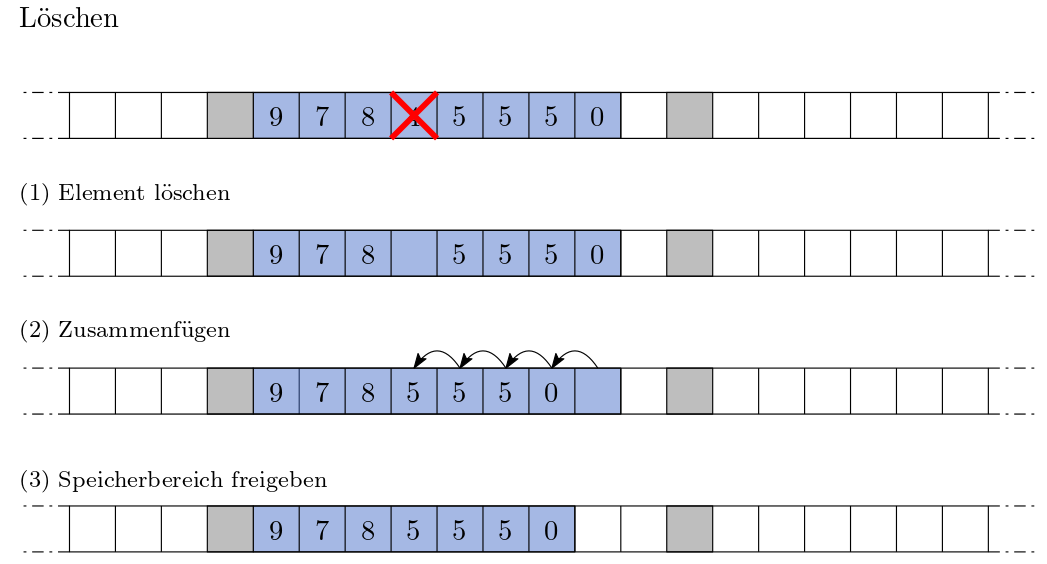
Abb. 12 Löschen#
Die Vorteile zeigen Effizienz beim Zugriff über einen Index. Die Nachteile offenbaren dagegen die Unflexibilität bei der Veränderung der Größe der Datenstruktur.
Dynamische Sammlungen im Speicher#
Anstatt die Sammlung durch einen zusammenhängenden Speicherbereich zu realisieren, gibt es eine zweite Möglichkeit: Die Realisierung über einen fragmentierten Speicherbereich, d.h. mehrere voneinander getrennte Speicherbereiche ergeben als Zusammenschluss die Sammlung. Die Daten der Datenstruktur können somit Kreuz und Quer im Speicher liegen.
Das erhöht die Flexibilität! Die Datenstruktur kann durch Speicherbereiche anwachsen die eben nicht zusammenhängen. Dadurch müssen wir Elemente nicht fortwährend verschieben. Die Sammlung kann dynamisch anwachsen und schrumpfen.
Damit die fragmentierten Teile als ganzes repräsentiert werden können, müssen sie verbunden werden. Dies wird durch sog. Zeiger/Pointer realisiert. Oft spricht man auch von einer Referenz. Dabei ist wichtig, dass ein Zeiger wiederum auf einen weiteren Zeiger zeigen/verweisen/referenzieren kann.
Ein Zeiger verbraucht selbstverständlich auch Speicher. Er liegt selbst an irgendeiner Speicheradresse und benötigt mindestens soviele Bits, die wir zur Repräsentation aller Adressen benötigen. Ist der Arbeitsspeicher 8 Byte groß und nehmen wir an wir können jeweils ein ganzes Byte addressieren, dann brauchen wir 8 Adressen. Somit verbraucht jede Adresse \(\left \lfloor{\log_2(8)}\right \rfloor = 3\) Bits.
In Abbildung 8 zeigt der Zeiger an Adresse 3 auf den Speicherbereich bei Adresse 7. Dies ist wiederum eine Adresse die auf den Speicherbereich 1 zeigt und dort liegt der Wert 0. Selbstverständlich bedarf es der richtigen Interpretation der jeweiligen Speicherbereiche, denn es könnte sich beim Wert bei Adresse 3 auch um den Dezimalwert 7 oder irgendetwas anderes als einen Zeiger handeln.
Für Zeiger gibt es keine perfekte Analogie aus der Realwelt, jedenfalls ist uns keine eingefallen. Probieren wir es mit unserer Schließfachanalogie: Nehmen sie eine große geordnete Anreihung von Schließfächern als Arbeitsspeicher. Jedes Schließfach hat eine eindeutige Nummer (Speicheradresse). In jedem Schließfach kann sich etwas befinden, unter anderem auch ein Zettel mit einer Schließfachnummer (Zeiger).
Das Problem an dieser Analogie ist jedoch, dass, wenn wir den Zettel in Händen halten, wir erst zum entsprechenden Schließfach gehen müssen. Dabei laufen wir an vielen anderen Schließfächern vorbei. Das kostet Zeit. Wenn wir allerdings einen Zeiger haben, so können wir auf den Wert unglaublich schnell zugreifen. Es kostet der CPU zwar auch etwas Zeit (bzw. Zyklen) um den Zeiger aufzulösen aber muss sie nicht über alle dazwischenliegenden Speicherbereiche „hinweglaufen“, d.h. iterieren.
Ein Zeiger ähnelt einer Schnur die sich zwischen zwei Schließfächern befindet. Bei Aktivierung des Zeigers werden wir direkt vom einen Schließfach zum anderen teleportiert! Allerdings funktioniert dies nur in eine Richtung. Die Schnur ist gerichtet!
Verkettete Listen im Speicher#
Wie können wir mit Zeigern eine Datenstruktur aus einem fragmentierten Speicherbereich bilden? Bleiben wir bei der Analogie der Schließfächer und Schnüre. Sie möchten ihre Lieblingsgerichte in alphabetischer Reihenfolge abspeichern. Dazu verwenden Sie die Schließfächer und Schnüre. Sie halten eine Schnur in den Händen, die auf das Schließfach mit Ihrem absoluten Lieblingsgericht zeigt. Das darauffolgende Schließfach verweist auf ihr zweitliebstes Gericht usw. Die so verketteten Schließfächer bilden eine sog. verkettete Liste (engl. Linked List).
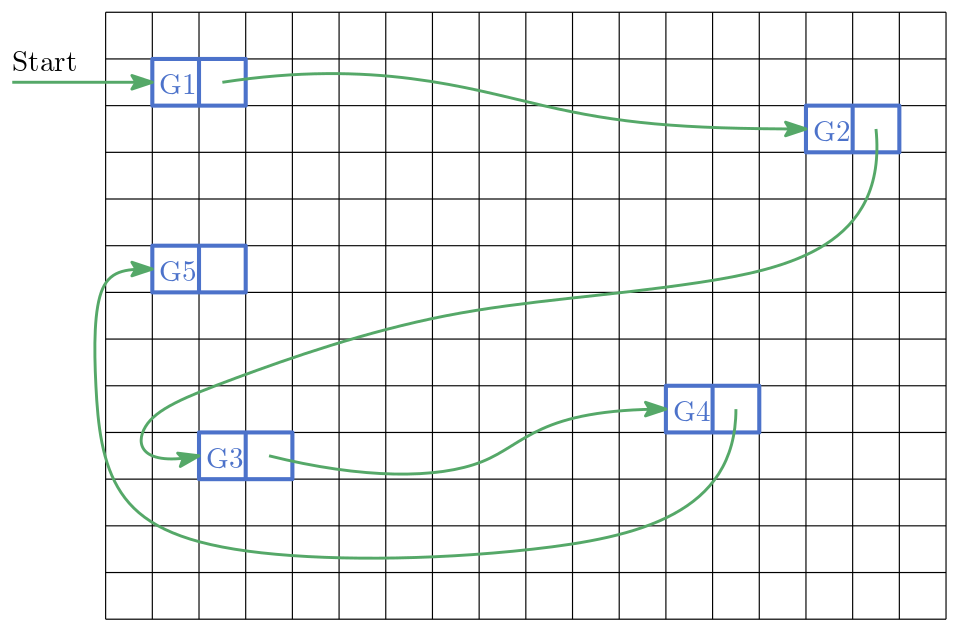
Abb. 13 Gerichte 1 bis 5 in einer verketteten Liste. Jede Kachel repräsentiert ein Schließfach bzw. einen adressierbaren Speicherbereich.#
Befinden Sie sich an einem Schließfach der Liste, so können Sie recht einfach ein neues Element an dieser Stelle einfügen. Eine verkettete Liste besteht aus sogenannten Knoten (Schließfach + Schnur zum nächsten Schließfach), welche durch Zeiger verbunden sind. Sie ist eine dynamische Sammlung, d.h. sie kann zur Laufzeit vergrößert und verkleinert werden.
Haben wir direkten Zugriff auf einen Knoten so können wir in die verkettete Liste ein neues Element, was direkt nachfolgt, effizient einfügen ohne dabei die anderen Elemente der Liste zu verschieben – ein wesentlicher Vorteil dieser Datenstruktur. Jeder Knoten besteht aus zwei Teilen:
- Daten
Der Wert des Knotens (oder auch ein Zeiger auf den Wert des Knotens). Das ist der Inhalt des Schließfachs.
- Zeiger
Verweist auf den nächsten Knoten. Das ist die Schnur, die zum nächsten Schließfach führt.
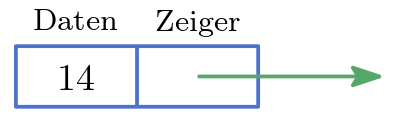
Abb. 14 Knoten einer verketteten Liste.#
Den Anfangsknoten der Liste bezeichnet man als Kopf/Head.

Abb. 15 Einer verkettete Liste aus Zahlen.#
Um Elemente am Ende (engl. Tail) einzufügen, kann es sinnvoll sein sich zusätzlich den letzten Knoten der Liste zu merken.
Zusammenfassung#
In diesem Kapitel haben wir gesehen:
Statische Sammlungen nutzen zusammenhängende Speicherbereiche für effizienten Indexzugriff, aber unflexible Größenänderungen
Dynamische Sammlungen nutzen fragmentierte Speicherbereiche mit Zeigern für flexible Größenänderungen, aber teurerem Zugriff
Verkettete Listen sind ein Beispiel für dynamische Sammlungen, die durch Zeiger verbundene Knoten verwenden
Diese Details helfen zu verstehen, warum bestimmte Operationen auf verschiedenen Datenstrukturen unterschiedlich effizient sind.