12.5. Abstraktionsgrad (S)#
Julia hat das Problem im Buy-Pfad mit High-Level-Funktionen aus pandas gelöst. Diese Funktionen kapseln komplexe Datenstrukturen und statistische Auswertungen – und ermöglichen dadurch eine sehr kompakte Implementierung.
Im Build-Pfad hat Julia viele Schritte selbst implementiert. Dort arbeitet sie eher „low-level“: einzelne Teilschritte werden explizit programmiert. Am Ende nutzt sie zusätzlich Standardbibliotheken wie statistics, die elementare statistische Funktionen bereitstellen.
Definition
High-Level-Funktionen beschreiben primär, was berechnet werden soll (z. B. „gib mir eine statistische Zusammenfassung“). Low-Level-Funktionen legen fest, wie etwas berechnet wird (z. B. Schleifen, Zwischenspeicher, Einzelschritte).
Wichtig: Das ist kein Entweder-oder, sondern eher ein Kontinuum – viele Funktionen liegen „dazwischen“.
Beispiele
High-Level:
DataFrame.describe()liefert eine komplette statistische Analyse „in einem Aufruf“.Zwischenstufe:
statistics.median()liefert eine einzelne Kenngröße – sie ist Baustein einer Analyse, aber nicht die ganze Analyse.Low-Level: eine eigene Median-/Quartilsberechnung per Sortieren/Indexieren/Schleifen legt die Rechenschritte selbst fest.
Julia muss erkennen, auf welchem Abstraktionsgrad sie gerade arbeitet: Verwendet sie Bausteine, die viel „für sie erledigen“, oder implementiert sie die einzelnen Schritte selbst?
In der Vorlesung und den Praktika sind Ihnen verschiedenen Python-Bibliotheken begegnet, die sich im Abstraktionsgrad und in ihrem Einsatzzweck unterscheiden. Die Grafik soll Sie dabei unterstützen, diese Bibliotheken einzuordnen und ihre Beziehungen zueinander zu verstehen.
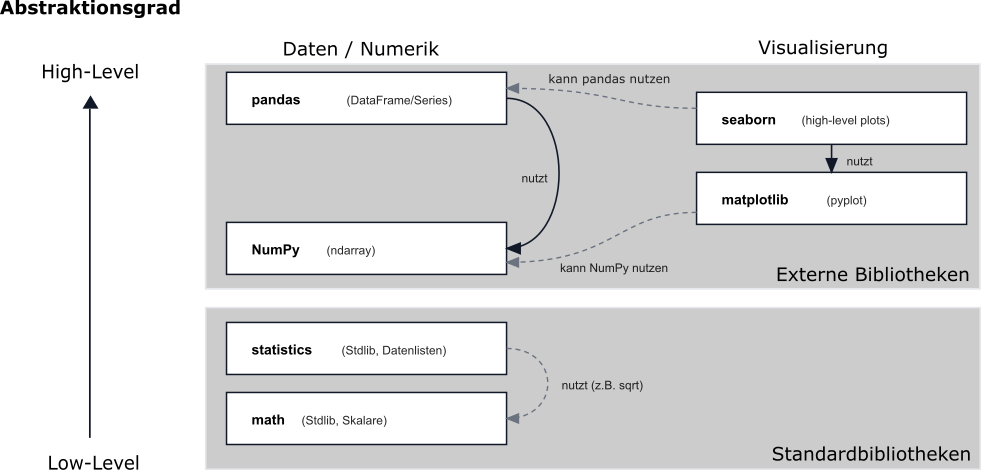
Abb. 12.8 Abstraktionsgrad: High-Level beschreibt was, Low-Level beschreibt wie.#
Die Grafik ordnet Bibliotheken nach Abstraktionsgrad (oben = „mehr erledigt für mich“, unten = „mehr Kontrolle, mehr Eigenarbeit“):
Daten/Numerik: Julia nutzt im Buy-Pfad
pandas(hoch).pandasbaut intern aufnumpyauf (niedriger). Für grundlegende Statistik nutzt Julia im Build-Pfadstatistics(Standardbibliothek), das wiederum auf einfachen mathematischen Bausteinen (z. B.math) aufsetzt.Visualisierung: Für Plots nutzt Julia
matplotlib. Für die Performance-Auswertung (Boxplot) verwendet sie zusätzlichseabornals High-Level-Schicht, die aufmatplotlibaufbaut.
Merksatz
Je höher der Abstraktionsgrad, desto schneller kommen Sie zu Ergebnissen – je niedriger, desto mehr bestimmen Sie das „Wie“.
Kurz zusammengefasst
High-Level-Funktionen beschreiben eher, was berechnet werden soll, und sparen Implementierungsarbeit.
Low-Level-Code legt fest, wie gerechnet wird, und bringt mehr Kontrolle (z. B. welche Methode für Quantile verwendet wird), aber auch mehr Aufwand.
Im Fallbeispiel nutzt Julia beide Ebenen: erst
pandas(hoch), dann Eigenimplementierung und Standardbibliothek (niedriger).