12.3. Lösung mit Library (V)#
Julia startet im Buy-Pfad: Sie möchte schnell zu einem Ergebnis kommen und nutzt dafür gut gepflegte Bibliotheken. Das ist in der Praxis oft die Standardwahl, solange Abhängigkeiten erlaubt sind und das Paket zuverlässig ist.
Kernidee
Julia beschreibt eher was sie will (Kennzahlen, Histogramm) und überlässt das wie der Library.
Hinweis
Sie führen den Code gerade auf einem Server aus. Deshalb können Sie nicht einfach Dateien von Ihrem Rechner-Pfad einlesen. Die Messdaten-Datei ist bereits für Sie online erreichbar.
Datenquelle festlegen
Julia greift über eine URL die Daten direkt als rohen Text ab.
Hinweis: die Variable csv_file_path liefert die Messdaten im Textformat.
csv_file_path = "https://gitlab.lrz.de/fk03ingenieurinformatik/ingenieurinformatik-buch-deploy-lrz/-/raw/master/data/air_quality_no2.csv"
# fallback, falls gitlab LRZ down:
# csv_file_path = "data/air_quality_no2.csv" # live code (fallback)
# image_file = "../air_quality_no2.csv" jupyterhub/binderhub
print(f"Die Datei wird bezogen über: {csv_file_path}")
Die Datei wird bezogen über: https://gitlab.lrz.de/fk03ingenieurinformatik/ingenieurinformatik-buch-deploy-lrz/-/raw/master/data/air_quality_no2.csv
CSV einlesen und inspizieren
Als Erstes liest Julia die Messdaten ein und verschafft sich einen Überblick.
import pandas as pd
df = pd.read_csv(
csv_file_path,
parse_dates=["datetime"]
)
df = df.rename(
columns={
"station_antwerp": "Antwerp",
"station_paris": "Paris",
"station_london": "London",
}
)
df.head()
| datetime | Antwerp | Paris | London | |
|---|---|---|---|---|
| 0 | 2019-05-07 02:00:00 | NaN | NaN | 23.0 |
| 1 | 2019-05-07 03:00:00 | 50.5 | 25.0 | 19.0 |
| 2 | 2019-05-07 04:00:00 | 45.0 | 27.7 | 19.0 |
| 3 | 2019-05-07 05:00:00 | NaN | 50.4 | 16.0 |
| 4 | 2019-05-07 06:00:00 | NaN | 61.9 | NaN |
Daten vorbereiten
Als Nächstes bereitet Julia die Daten so vor, dass Zeitpunkte bequem als Index genutzt werden können.
df = df.set_index("datetime")
df.head()
| Antwerp | Paris | London | |
|---|---|---|---|
| datetime | |||
| 2019-05-07 02:00:00 | NaN | NaN | 23.0 |
| 2019-05-07 03:00:00 | 50.5 | 25.0 | 19.0 |
| 2019-05-07 04:00:00 | 45.0 | 27.7 | 19.0 |
| 2019-05-07 05:00:00 | NaN | 50.4 | 16.0 |
| 2019-05-07 06:00:00 | NaN | 61.9 | NaN |
Kennzahlen berechnen
Dann lässt sich Julia zentrale Kennwerte automatisch berechnen (z. B. Mittelwert, Standardabweichung und Quartile (Q1, Median, Q3)).
stats = df.describe().T
stats
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Antwerp | 95.0 | 25.778947 | 12.682019 | 7.5 | 16.75 | 23.00 | 34.500 | 74.5 |
| Paris | 1004.0 | 27.740538 | 15.285746 | 0.0 | 16.50 | 24.15 | 35.925 | 97.0 |
| London | 969.0 | 24.777090 | 11.214377 | 0.0 | 19.00 | 25.00 | 31.000 | 97.0 |
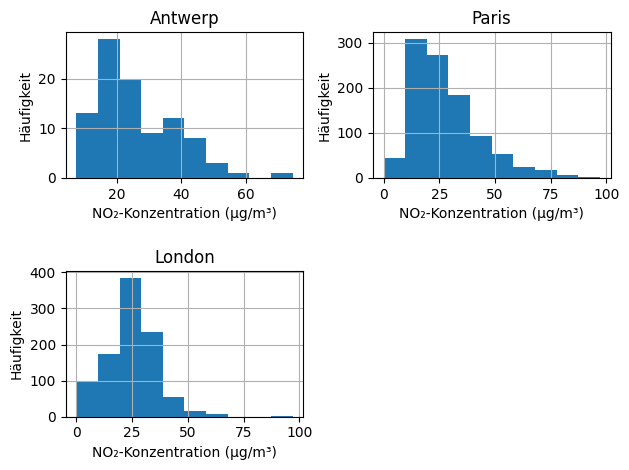
Verteilung visualisieren
Zum Abschluss visualisiert Julia die Verteilung der Messwerte als Histogramme.
import matplotlib.pyplot as plt
axs = df.hist()
for ax in axs.ravel():
ax.set_xlabel("NO₂-Konzentration (µg/m³)")
ax.set_ylabel("Häufigkeit")
plt.tight_layout(h_pad=2.0, w_pad=1.0)
plt.show()
Kurz gefasst
Julia löst die Aufgabe im Buy-Pfad mit wenigen, gut getesteten Bibliotheksaufrufen.
Julia bekommt Einlesen, Kennzahlen und Histogramme, ohne die Algorithmen selbst zu implementieren.
Julia profitiert vom hohen Abstraktionsgrad: Der Code ist kurz, aber sie ist an die Library gebunden.