2.6.2. Datenstrukturen (A)#
Hinweis
In diesem Abschnitt geben wir eine Einführung dazu wie Daten in Python strukturiert werden können. Mit den Informationen aus dem Teilabschnitt Wie gehts das nun in Python? können Sie im Praktikum schon einmal losarbeiten. Details dazu lernen wir dann im Kapitel Datentypen kennen.
Programme arbeiten nicht nur mit Anweisungen, sondern ständig mit Daten. Daten können sehr unterschiedlich aussehen:
my_name = "Christina"
height = 170
g = 9.81
Die zentrale Frage ist:
Zentrale Frage
Wie organisiert man viele und auch zusammenhängende Daten so, dass ein Programm sinnvoll und effizient mit ihnen arbeiten kann?

Abb. 2.17 Unterschiedliche Situationen erfordern unterschiedliche Datenstrukturen.#
Das Bild zeigt: Es gibt keine „beste“ Datenstruktur, sondern nur eine passende für eine gegebene Aufgabe.
Eine Queue ist passend, wenn Elemente in der Reihenfolge verarbeitet werden sollen, in der sie eintreffen.
Ein Set ist passend, wenn nur relevant ist, ob ein Element vorhanden ist oder nicht.
Eine Map ist passend, wenn Daten über einen Schlüssel wiedergefunden werden sollen.
Ein Stack ist passend, wenn das zuletzt eingefügte Element zuerst wieder entfernt werden soll.
Diese Prinzipien tauchen im Alltag oft in konkreten Situationen auf.
Eine Queue wird z. B. bei Aufträgen, Simulationen oder Datenströmen verwendet.
Ein Set beantwortet effizient die Frage „Ist dieses Element enthalten?“
Eine Map folgt dem Prinzip „Schlüssel → Wert“, z. B. wie in Tabellen oder Telefonbüchern.
Ein Stack ist auch im Computer selbst zentral, z. B. bei Funktionsaufrufen und Rücksprungadressen.
Definition: Abstrakter Datentyp (ADT)
Queue, Set, Map und Stack sind abstrakte Datentypen (ADTs).
Sie beschreiben, welche Operationen auf einer Struktur erlaubt sind (z. B. Einfügen, Entfernen, Suchen).
Sie beschreiben, welche Regeln dabei gelten (z. B. Reihenfolge beim Entfernen).
Sie sagen nicht, wie die Struktur intern im Speicher umgesetzt ist.
Neben Queue, Set, Map und Stack gibt es weitere ADTs, z. B. Trees (Bäume).
2.6.2.1. Speicherrepräsentation#
Damit ein Computer diese abstrakten Ordnungen umsetzen kann, müssen sie konkret im Arbeitsspeicher realisiert werden.
Entscheidend ist, wie diese Bits angeordnet sind und wie auf sie zugegriffen wird.
Eine grundlegende Unterscheidung ist die zwischen statischen und dynamischen Sammlungen.
Statische Sammlungen
Statische Sammlungen besitzen eine feste Größe.
Der benötigte Speicher wird einmal reserviert.
Die Größe kann sich zur Laufzeit nicht verändern.
Die Elemente liegen typischerweise zusammenhängend im Speicher.
In unserem Beispiel ist es die Zahlenfolge 9-7-8-4-5-5-5-0.
Alle Zahlen liegen nebeneinander im Speicher.
Beim Einfügen zwischen 4 und 5 muss Platz vorhanden sein, oder es muss umorganisiert werden.
Variante 1: Platz nebenan ist frei.
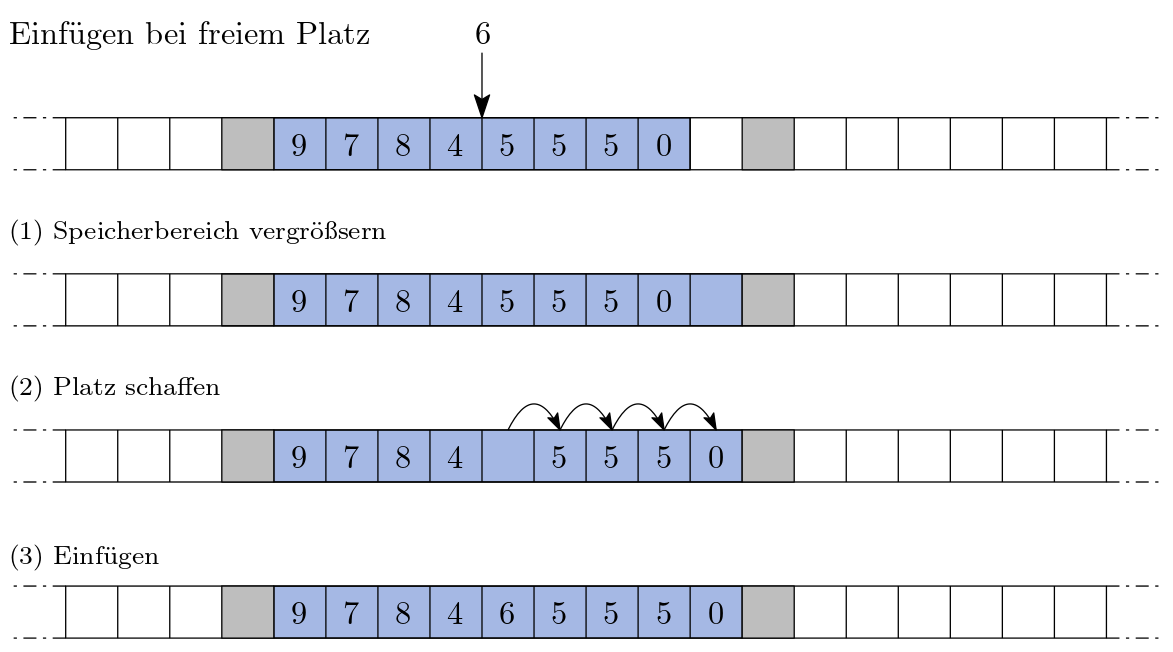
Abb. 2.18 Einfügen in eine statische Struktur: rechts daneben ist noch Speicher frei.#
Variante 2: Platz nebenan ist belegt.
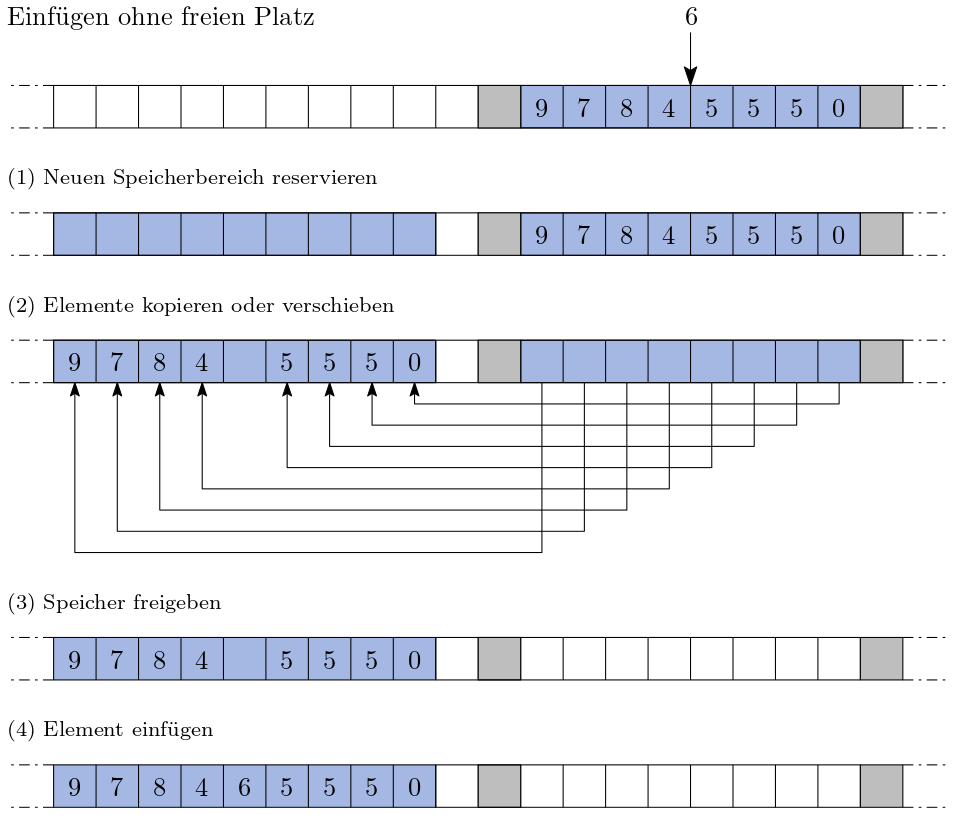
Abb. 2.19 Einfügen in eine statische Struktur: rechts daneben ist kein Speicher frei (Umkopieren/Neuanordnung nötig).#
Dynamische Sammlungen
Eine dynamische Sammlung ist eine Sammlung, deren Größe sich während der Programmausführung ändern kann.
Sie kann wachsen oder schrumpfen.
Die Umsetzung im Speicher hängt von der konkreten Datenstruktur ab.
Häufig werden Verweise/Zeiger verwendet, um Elemente logisch zu verbinden.
Ein einfaches Beispiel ist eine verkettete Liste.
Jedes Element (Knoten) enthält Daten und einen Zeiger auf das nächste Element.
Zusätzlich gibt es einen Startzeiger (Head) auf das erste Element.
Der Zeiger von G1 enthält (vereinfacht) die Speicheradresse von G2.
Das letzte Element zeigt auf „nichts“ (z. B.
null/None).
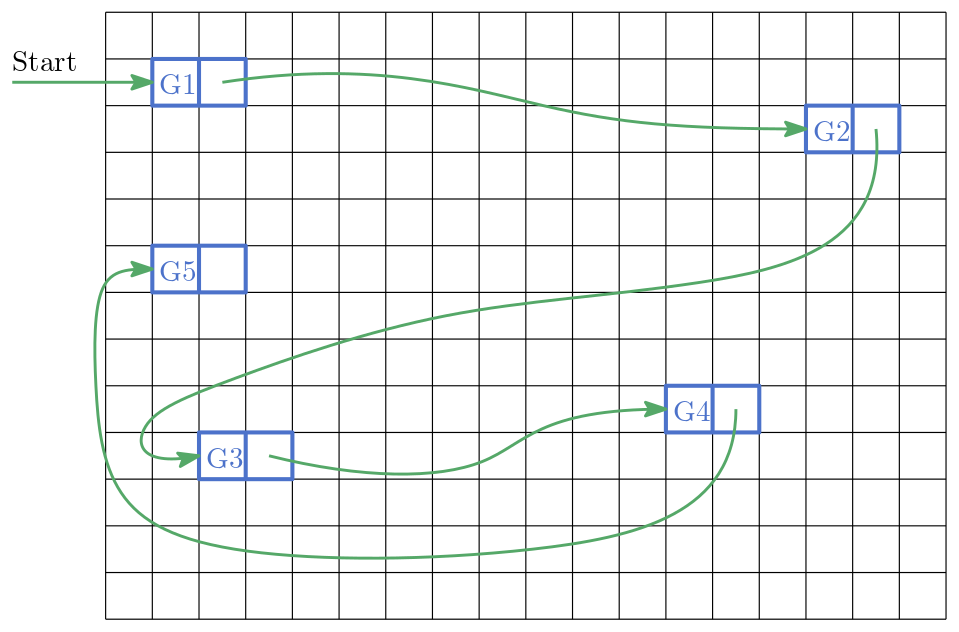
Abb. 2.20 Beispiel einer verketteten Liste: Knoten enthalten Daten und einen Zeiger auf den nächsten Knoten.#
Hinweis
Datenstrukturen sind Werkzeuge zur Organisation von Information.
Abstrakte Datentypen beschreiben das gewünschte Verhalten.
Implementierungen beschreiben die konkrete Umsetzung im Speicher.
Die Wahl der Datenstruktur bestimmt, ob ein Problem einfach oder unnötig kompliziert gelöst werden kann.
2.6.2.2. Wie gehts das nun in Python?#
Abstrakte Datenstrukturen (ADT) beschreiben was eine Datenstruktur leisten soll, unabhängig von Programmiersprache und Speicher.
Datentypen (z. B. list, tuple) sind sprachabhängige Umsetzungen eines ADT und legen fest, wie Programme mit den Daten arbeiten können.
Mehrere Datentypen können denselben ADT umsetzen, sich aber z. B. in Veränderbarkeit, erlaubten Operationen oder Garantien unterscheiden.
Die Speicherrepräsentation bestimmt, wie ein Datentyp intern abgelegt ist, und beeinflusst Performance, Speicherbedarf und Verhalten.
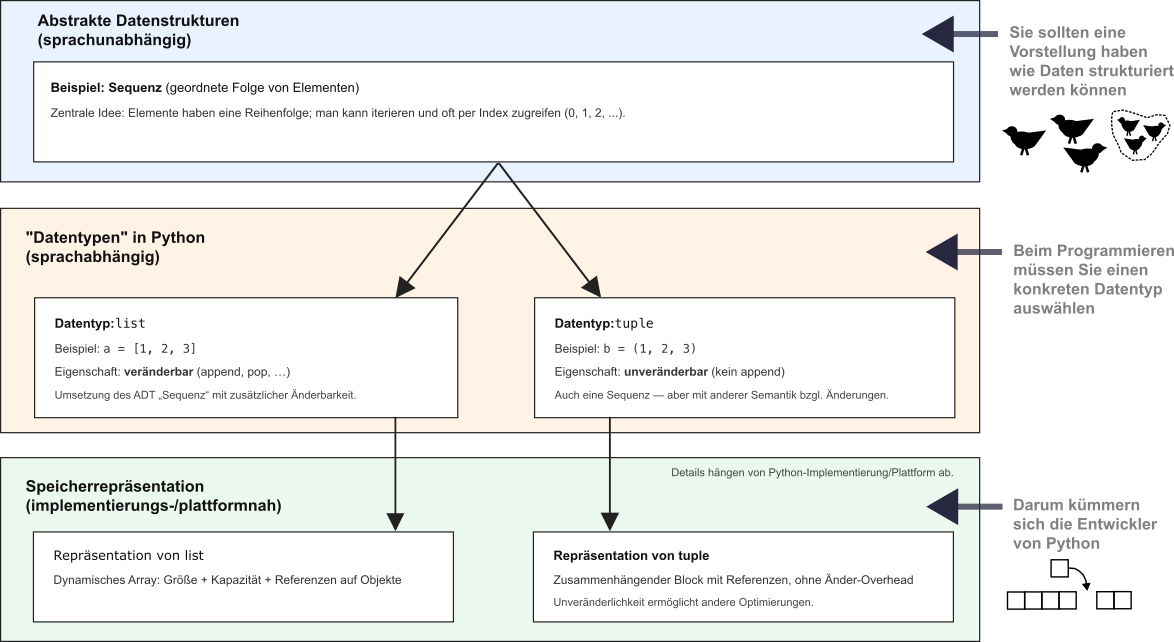
Abb. 2.21 Abstrakte Datenstrukturen - Datentypen - Speicherrepräsentationen.#
Wichtig
Gleiche Bedeutung heißt nicht gleiche Umsetzung – wer ADT, Datentyp und Speicherrepräsentation nicht trennt, riskiert ineffiziente oder fehlerhafte Systeme.
Beispiele für Datentypen, die Sie in Python häufig brauchen werden:
2.6.2.2.1. list (Sequenz mit Reihenfolge)#
Abstrakte Idee:
Wir wollen Elemente in einer festen Reihenfolge abspeichern und die Elemente verändern können:
Man möchte über die Position in der Liste („Element an Stelle 2“ = „Index = 2“) auf die Elemente zugreifen
Man kann Elemente anhängen, ändern oder entfernen
# Eine Liste hält Werte in einer geordneten Reihenfolge.
zahlen = [9, 7, 8, 4, 7, 2, 1 , 7, 5]
print("Start:", zahlen)
# Element anhängen
zahlen.append(5)
print("Nach append(5):", zahlen)
# Element an Position 1 ändern
zahlen[1] = 70
print("Nach Änderung an Index 1:", zahlen)
# Einfügen an einer bestimmten Position
zahlen.insert(2, 99)
print("Nach insert(2, 99):", zahlen)
# Zugriff über Index
print("Element an Index 0:", zahlen[0])
print("Letztes Element:", zahlen[-1])
Start: [9, 7, 8, 4, 7, 2, 1, 7, 5]
Nach append(5): [9, 7, 8, 4, 7, 2, 1, 7, 5, 5]
Nach Änderung an Index 1: [9, 70, 8, 4, 7, 2, 1, 7, 5, 5]
Nach insert(2, 99): [9, 70, 99, 8, 4, 7, 2, 1, 7, 5, 5]
Element an Index 0: 9
Letztes Element: 5
2.6.2.2.2. set (Menge ohne Duplikate)#
Abstrakte Idee:
Ein set modelliert eine mathematische Menge. Eigenschaften:
die Reihenfolge der Elemente ist egal
jedes Element kommt höchstens einmal vor
# Ein Set enthält jedes Element maximal einmal.
tags = {"python", "daten", "python", "algo"}
print("Start-Set:", tags)
# Neues Element hinzufügen
tags.add("strukturen")
print("Nach add('strukturen'):", tags)
# Duplikat hinzufügen (ändert nichts)
tags.add("python")
print("Nach erneutem add('python'):", tags)
# Enthalten-Prüfung
print("'algo' enthalten?", "algo" in tags)
print("'java' enthalten?", "java" in tags)
# Mengenoperationen
andere = {"python", "oop", "algo"}
print("Schnittmenge:", tags & andere)
print("Vereinigung:", tags | andere)
Start-Set: {'algo', 'daten', 'python'}
Nach add('strukturen'): {'strukturen', 'algo', 'daten', 'python'}
Nach erneutem add('python'): {'strukturen', 'algo', 'daten', 'python'}
'algo' enthalten? True
'java' enthalten? False
Schnittmenge: {'algo', 'python'}
Vereinigung: {'python', 'oop', 'algo', 'daten', 'strukturen'}
Hinweis
Eine umfassende Übersicht zu Datentypen und deren Details lernen wir im Kapitel Datentypen kennen.